pickle反序列化
面试的时候被问到不太答得上来就想着学一学,正好BUU刷到了题,就学一学这个漏洞,感觉了解过php反序列化的再对python语言有点了解之后会比较好上手,可以类比php反序列化学习
下面是学习的一些网站,大致从5个方面浅析pickle反序列化可以参考原文
什么是pickle
Pickle是Python内置的序列化/反序列化的模块,作用是将任意python对象转换为二进制流并还原,也能将字节流还原为原始对象,常用于对象持久化、进程间通信等场景
pickle模块不安全,只有在信任数据源时才能使用。恶意构造的pickle数据可以在反序列化时执行任意代码
但pickle的设计初衷是“信任环境内的对象交换”,而非“不可信数据解析”——其反序列化过程会主动执行对象关联的代码,这一特性使其成为黑客攻击的突破口,即Pickle反序列化漏洞:恶意构造的Pickle字节流,可在反序列化时触发任意代码执行,进而控制目标主机
但是要区别pickle不是“数据格式化转换器(如JSON)”,而是“对象构造器”即反序列化时,它会根据字节流中的指令,一步步重建对象,而这个“重建过程”会主动调用Python的内置方法和函数,若指令被篡改,就会执行恶意代码
简单补充一下pickle和JSON的区别:JSON只能表示基本类型(数值、字符串、列表、字典等),而Pickle能够序列化几乎任意Python对象(类实例、函数、复杂数据结构等)
对比项 Pickle JSON 可存储类型 任意 Python 对象(类、函数、集合等) 基本数据类型(数字、字符串、数组、字典) 跨语言性 Python 专用 跨语言 安全性 反序列化可执行代码 → 有安全风险 相对安全(只解析数据)
对于反序列化这里就不多赘述了,之前学过php反序列化时已经大致了解,简单来说把“对象 -> 字符串”的翻译过程称为“序列化”;相应地,把“字符串 -> 对象”的过程称为“反序列化”。需要保存一个对象的时候,就把它序列化变成字符串;需要从字符串中提取一个对象的时候,就把它反序列化
在对象协议方面,Python允许类定义特殊方法来自定义序列化行为:
__getstate__/__setstate__: 当需要自定义实例状态存取时使__reduce__/__reduce_ex__: 在反序列化时自动调用,返回描述如何重构对象的可调用对象和参数元组,使得Pickle可以调用这个可调用对象并传入参数来重新创建实例 。例如,__reduce__()可以返回(func, args),Pickle在加载时会执行func(*args)来重建对象 。如果__reduce__返回了额外的状态值,Unpickler在创建对象后会调用该对象的__setstate__方法来设置状态 。在Python 3.x中,__reduce_ex__(protocol)优先于__reduce__,允许针对不同协议版本定制返回值
基本用法
python的pickle模块用于反序列化的两个函数
pickle.dumps():序列化pickle.loads():反序列化
序列化对象
使用 pickle.dumps() 方法可以将 Python 对象序列化并保存到文件中
1 | |
'wb'表示以二进制写模式打开文件。pickle.dumps()将data对象序列化并写入文件
反序列化对象
1 | |
'rb'表示以二进制读模式打开文件。pickle.load()从文件中读取字节流并反序列化为 Python 对象
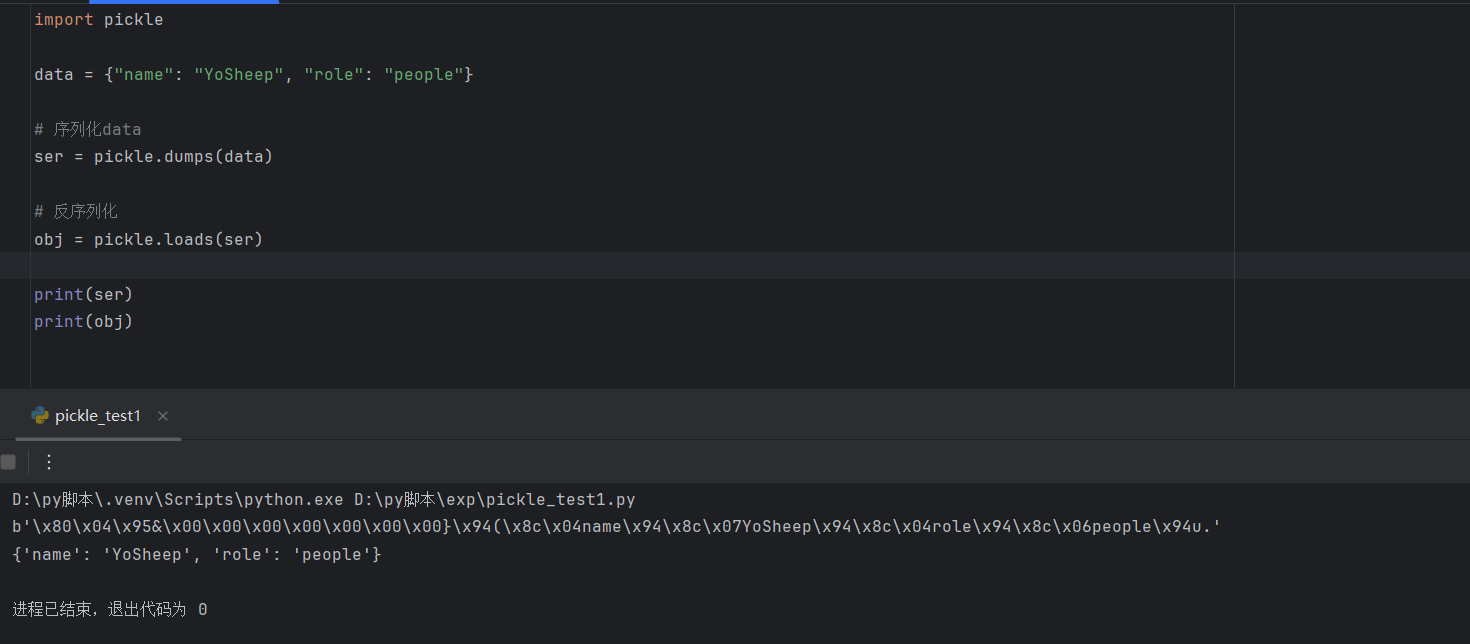
可以看到这里与php反序列化不同的是,python序列化后的结果并没有之前我们所规定的属性
对文件的反序列化
1 | |
1 | |
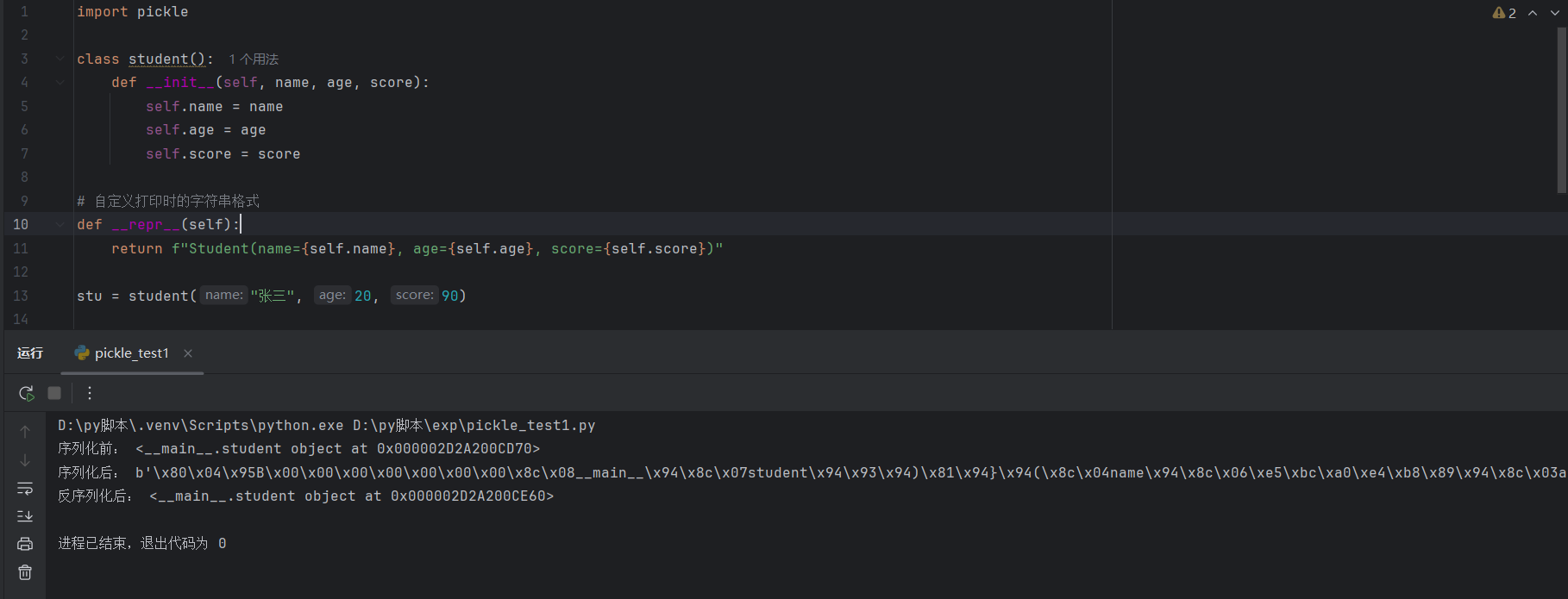
该对象经历了一个:对象 -> 二进制数据 -> 对象的过程
可序列化的对象类型
Pickle 可以序列化大多数 Python 对象,包括:
- 基本数据类型:整数、浮点数、字符串、布尔值、None
- 集合类型:列表、元组、字典、集合
- 自定义类的实例
- 函数和类(有一定限制)
1 | |
序列化自定义类
1 | |
序列化多个对象
可以多次调用 pickle.dumps() 来保存多个对象
1 | |
pickle模块常用方法
| 方法 | 说明 | 示例 |
|---|---|---|
pickle.dump(obj, file) |
将对象序列化并写入文件 | pickle.dump(data, open('data.pkl', 'wb')) |
pickle.load(file) |
从文件读取并反序列化对象 | data = pickle.load(open('data.pkl', 'rb')) |
pickle.dumps(obj) |
将对象序列化为字节串 | bytes_data = pickle.dumps([1, 2, 3]) |
pickle.loads(bytes) |
从字节串反序列化对象 | lst = pickle.loads(bytes_data) |
pickle.HIGHEST_PROTOCOL |
可用的最高协议版本(属性) | pickle.dump(..., protocol=pickle.HIGHEST_PROTOCOL) |
pickle.DEFAULT_PROTOCOL |
默认协议版本(属性,通常为4) | pickle.dumps(obj, protocol=pickle.DEFAULT_PROTOCOL) |
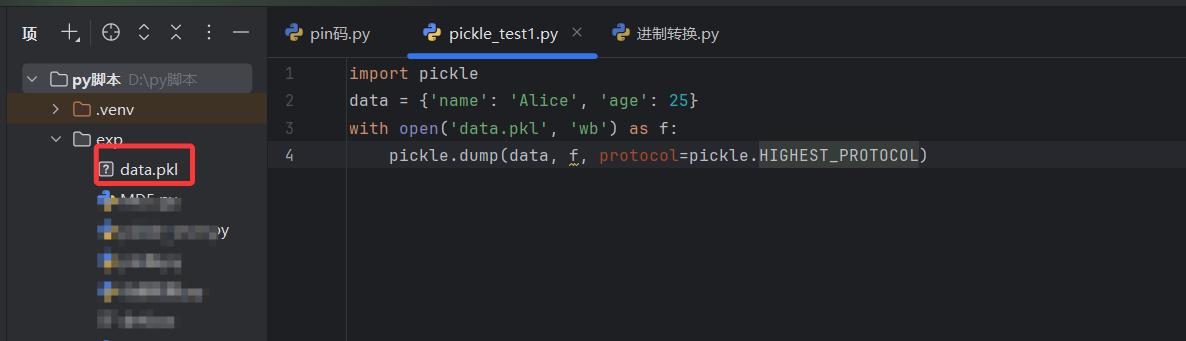
序列化对象到文件
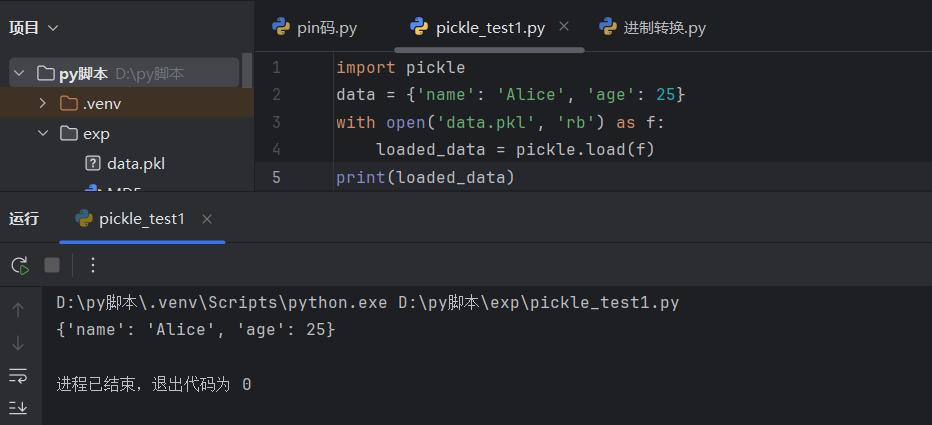
将一个字典对象序列化并保存到文件 data.pkl 中
1 | |
从文件反序列化
1 | |
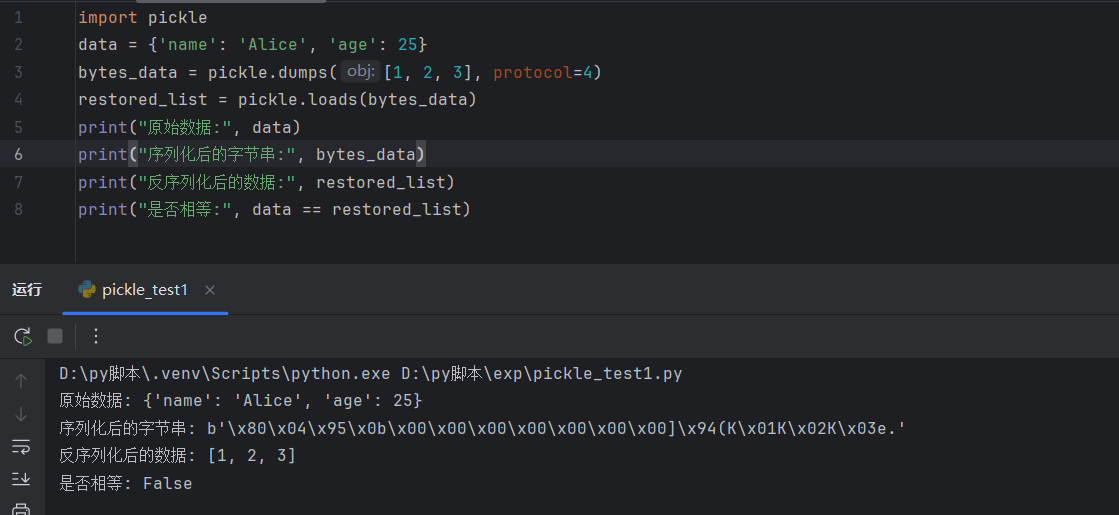
序列化为字节串
1 | |
漏洞原理
反序列化即执行指令
pickle反序列化遵循“指令驱动”逻辑,字节流中包含的不是原始数据而是“如何构造对象的步骤”
关键危险点在于:
- 触发特殊方法:若反序列化的对象定义了
__reduce__方法,pickle会自动调用该方法,其返回值(通常是元组)会被当作“构造对象的指令”——元组的第一个元素是可调用对象(如函数、类),后续元素是该对象的参数,pickle会执行可调用对象(参数)的操作 - 引用全局对象:pickle会直接引用序列化时记录的全局变量(如模块、函数),若这些全局变量被恶意替换(如将
os.system伪装成普通函数),反序列化时会执行恶意逻辑 - 无数据校验:pickle不验证字节流的合法性,无论内容是否包含恶意指令,都会按步骤执行
注:另一种原理解释
Pickle反序列化过程相当于一个完整的虚拟机(Pickle VM,简称PVM)在Python解释器中执行字节码序列 。PVM维护一个指令解析器(依次读取并执行操作码)、一个使用Python list 实现的操作栈(临时存储数据和中间结果)、以及一个使用Python dict 实现的memo(对象缓存,用于避免重复反序列化同一对象)。在解析字节流时,每遇到一个操作码(opcode),就执行相应操作并更新栈或memo,直到遇到终止符(
.)为止,最终栈顶的对象即为反序列化结果这里讲到了栈和PVM感觉有点点难懂
通俗点说就是Pickle 反序列化就像是在 Python 里运行一个迷你“虚拟机”。
它会一条一条地读取序列化数据中的指令(就像程序的字节码),
然后按照这些指令往一个“临时工作台”(叫操作栈)上放东西、做计算,
同时还会用一个“备忘录”(叫 memo)记住已经处理过的对象,避免重复干活。
一直执行到遇到结束标记(.)为止,最后“工作台”最上面的那个东西,就是还原出来的原始对象。简单来说:Pickle 不是直接“读回”数据,而是“重演”创建这个对象的过程——而这个过程可能包含任意代码,所以很危险
魔术方法
python魔术方法
构造方法__new__
- 调用时机:在实例化一个类时自动被调用,是类的构造方法
- 作用:可以通过重写
__new__自定义类的实例化过程
初始化方法__init__
- 调用时机:在
__new__方法之后被调用,主要负责定义类的属性,以初始化实例 - 用法
1 | |
析构方法__del__
类比php中的__destruct()魔术方法
- 调用时机:在实例化销毁时调用,只在实例的所有调用结束后才会被调用
__getattr__
类比php的__get()魔术方法
- 调用时机:获取不存在的对象属性时触发
- 特点:存在返回值
__setattr__
- 调用时机:设置对象成员值的时候触发
- 用法
1 | |
__repr__
- 调用时机:在实例被传入
repr()时被调用 - 返回值:必须返回字符串
__call__
类比php反序列化的__invoke()方法
- 调用时机:把对象当作函数调用时触发
__len__
- 调用时机:被传入len()时调用
- 返回值:返回一个整型
__str__
- 调用时机:被str()、format()、print()调用时调用,返回一个字符串
python的特殊属性
object.__dict__
一个字典或其他类型的映射对象,用于存储对象的(可写)属性
instance.__class__
类实例所属的类
class.__bases__
由类对象的基类所组成的元组
definition.__name__
类、函数、方法、描述器或生成器实例的名称
definition.__qualname__
类、函数、方法、描述器或生成器实例的 qualified name
__reduce__是序列化协议的核心方法
pickle模块在序列化对象时会调用对象的__reduce__方法(如果存在),class的__reduce__方法,在pickle反序列化的时候会被执行。其底层的编码方法,就是利用了R指令码。 f要么返回字符串,要么返回一个tuple,后者对我们而言更有用。该方法返回一个元组,用于告诉pickle如何重建对象:
- 第一个元素时可调用对象(如函数、类等)
- 第二个元素时调用该可调用对象的参数(元组形式)
- 后续元素可选(如用于
__setstate__的状态)
攻击者可利用这点执行任意代码
1 | |
__reduce__的底层控制权
__reduce__直接暴露了对象重建的底层逻辑:
- 直接指定可调用对象和参数:攻击者可以完全控制反序列化时执行的函数(如os.system,subprocess.call等)
- 绕过高层抽象:不需要依赖对象本身的逻辑,只需构造
__reduce__返回的元组即可
其他魔术方法的局限
Python对象有许多魔术方法(如__init__、__new__、__setstate__等),但在反序列化过程中的行为受限
__init__和__new__- 作用:初始化对象
- 局限:无法直接执行外部系统命令
攻击者需要依赖类的本身行为,而pickle默认不会对这些方法执行任意代码
__setstate__- 作用:恢复对象的状态(通过
__getstate__保存的状态) - 局限:输入的是序列化时保存的状态
- 作用:恢复对象的状态(通过
攻击者需要构造特定的状态数据,且执行能力有限
__getattr__和__getattribute__- 作用:处理属性访问
- 局限:不直接参与反序列化过程
栈
栈是一种存储数据的结构.栈有压栈和弹栈两种操作
PVM
pickle是一种栈语言,它由一串串opcode(指令集)组成.该语言的解析是依靠Pickle Virtual Machine(PVM)进行的
PVM由以下三部分组成
- 指令处理器:从流中读取
opcode和参数,并对其进行解释处理。重复这个动作,直到遇到 . 这个结束符后停止。 最终留在栈顶的值将被作为反序列化对象返回。 - stack:由 Python 的
list实现,被用来临时存储数据、参数以及对象。 - memo:由 Python 的
dict实现,为 PVM 的整个生命周期提供存储
常见的opcode
| 指令 | 描述 | 具体写法 | 栈上的变化 |
|---|---|---|---|
| c | 获取一个全局对象或import一个模块 | c[module]\n[instance]\n | 获得的对象入栈 |
| o | 寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象) | o | 这个过程中涉及到的数据都出栈,函数的返回值(或生成的对象)入栈 |
| i | 相当于c和o的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象) | i[module]\n[callable]\n | 这个过程中涉及到的数据都出栈,函数返回值(或生成的对象)入栈 |
| N | 实例化一个None | N | 获得的对象入栈 |
| S | 实例化一个字符串对象 | S’xxx’\n(也可以使用双引号、’等python字符串形式) | 获得的对象入栈 |
| V | 实例化一个UNICODE字符串对象 | Vxxx\n | 获得的对象入栈 |
| I | 实例化一个int对象 | Ixxx\n | 获得的对象入栈 |
| F | 实例化一个float对象 | Fx.x\n | 获得的对象入栈 |
| R | 选择栈上的第一个对象作为函数、第二个对象作为参数(第二个对象必须为元组),然后调用该函数 | R | 函数和参数出栈,函数的返回值入栈 |
| . | 程序结束,栈顶的一个元素作为pickle.loads()的返回值 | . | 无 |
| ( | 向栈中压入一个MARK标记 | ( | MARK标记入栈 |
| t | 寻找栈中的上一个MARK,并组合之间的数据为元组 | t | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| ) | 向栈中直接压入一个空元组 | ) | 空元组入栈 |
| l | 寻找栈中的上一个MARK,并组合之间的数据为列表 | l | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| ] | 向栈中直接压入一个空列表 | ] | 空列表入栈 |
| d | 寻找栈中的上一个MARK,并组合之间的数据为字典(数据必须有偶数个,即呈key-value对) | d | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| } | 向栈中直接压入一个空字典 | } | 空字典入栈 |
| p | 将栈顶对象储存至memo_n | pn\n | 无 |
| g | 将memo_n的对象压栈 | gn\n | 对象被压栈 |
| 0 | 丢弃栈顶对象 | 0 | 栈顶对象被丢弃 |
| b | 使用栈中的第一个元素(储存多个属性名: 属性值的字典)对第二个元素(对象实例)进行属性设置 | b | 栈上第一个元素出栈 |
| s | 将栈的第一个和第二个对象作为key-value对,添加或更新到栈的第三个对象(必须为列表或字典,列表以数字作为key)中 | s | 第一、二个元素出栈,第三个元素(列表或字典)添加新值或被更新 |
| u | 寻找栈中的上一个MARK,组合之间的数据(数据必须有偶数个,即呈key-value对)并全部添加或更新到该MARK之前的一个元素(必须为字典)中 | u | MARK标记以及被组合的数据出栈,字典被更新 |
比较全的指令集(从网上搬的其他师傅的)
1 | |
漏洞利用
变量覆盖
若存在类Secret,类有一个name属性,那我们可以通过pickle反序列化修改这个属性的值
1 | |
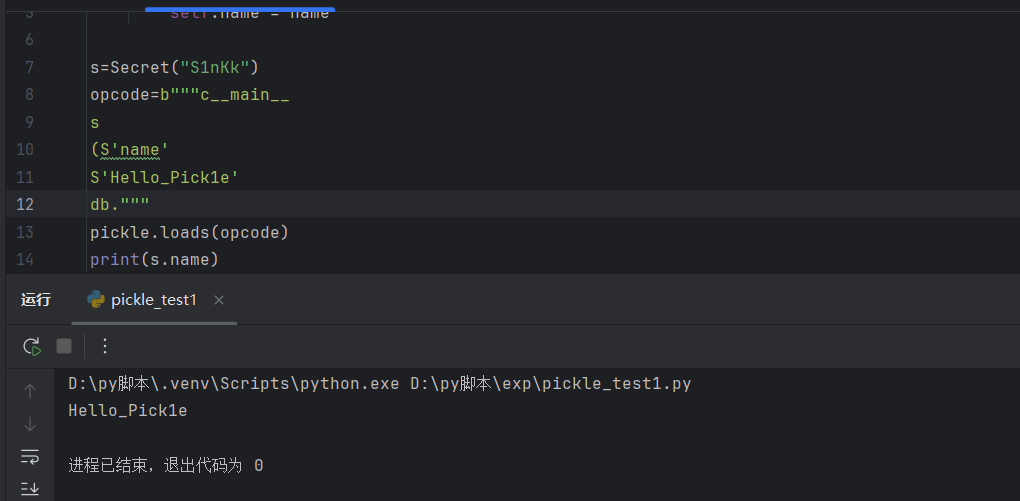
成功输出Hello_Pick1e,表示成功篡改属性
opcode(恶意字节码分析)
1 | |
c__main__- pickle指令:global
- 实际含义:加载
__main__模块中的对象
s- 实际含义:指定要在的对象名是s(即之前创建的Secret的实例)
(S'name'- pickle指令:mark+string
- 实际含义:标记开始,压入键’name’到栈
S'Hello_Pick1e'- pickle指令:string
- 实际含义:压入值
'Hello_Pick1e'到栈
d- pickle指令:setitem
- 实际含义:执行
s['name'] = 'Hello_Pick1e'(等价于修改实例属性s.name)
b.- pickle指令:build+stop
- 实际含义:构建并结束执行
RCE
可以使用R,i,o,b等操作码实现命令执行
c操作符
这是用的最多的,其中final_class()函数很关键,在对危险函数的过滤和绕过中也会涉及
1 | |
1 | |
c操作符把final_class()函数返回的一个类对象压入栈,通过__inport__()引入了模块并且通过self.proto判断pickle版本处理了不同版本的函数名称问题
R操作符
源码
1 | |
利用R操作符构造payload模板
1 | |
c- pickle指令:global指令
- 作用:用于加载模块、类、可调用对象(不如os.system)
<module>- 作用:要加载的模块名(不如
os)
- 作用:要加载的模块名(不如
<callable>- 作用:模块中的可调用对象(比如
system)
- 作用:模块中的可调用对象(比如
(- pickle指令:mark指令
- 作用:标记参数开始
<args>- 作用:传给可调用对象的参数(比如
whoami或rm -rf /)
- 作用:传给可调用对象的参数(比如
t- pickle指令:tuple指令
- 作用:把栈中的参数打包成元组
R- pickle指令:reduce指令,核心指令
- 作用:执行
challenge(*args)即调用函数并传参
.- pickle指令:stop指令
- 作用:结束执行
示例
1 | |
o操作符
1 | |
寻找栈中的MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象)
i操作符
1 | |
self.find_class(module, name):执行__import__(module)加载模块,再去模块中的name属性(即类或函数)self.pop_mark():pickle用栈存储数据,pop_mark()会取出从最近一个MARK((操作符)到当前栈顶的所有数据,作为实例化的参数self._instantiate(klass,args):等价于执行klass(*args),创建类的实例
示例
正常实例化自定义类
1 | |
正常情况下,i操作符加载__main__.Secret,传入参数’S1nKk’,实例化出Secret对象
恶意利用i操作符实现rce
1 | |
恶意构造代码后,i操作符加载subprocess.Popen,传入参数whoami,执行后会执行RCE
b操作符
1 | |
b操作的用法
- 向一个实例中插入属性,或覆盖属性
- 以一个实例的
__setstate__属性func,b的前一个元素当作arg,执行func(arg)
b操作符的工作方式
- 弹栈,这里的元素是state
- 取栈顶元素,此元素为
setstate,此元素可以是一个实例也可以是一个字典,如果是实例,就会尝试获取这个实例的__setstate__属性的值 __setstate__存在执行setstate(state)__setstate__不存在- 判断state类型,若是元组,并且元组中只有两个元素,那么就按顺序给state和字典中的键值对给
inst.__dict__更新属性的值 - 如果
slotstate是一个字典,那么根据slotstate的键值对给inst更新属性的值
- 判断state类型,若是元组,并且元组中只有两个元素,那么就按顺序给state和字典中的键值对给
- 如果不是元组,那么就根据state字典中的值更新
inst.__dict__的值
因为存在这个功能,b操作符就可以用来进行命令执行
1 | |
b操作符使用模板
1 | |
函数黑名单绕过
重写find_class()
思路一 获取危险函数
绕过显式字符串检测
v操作符可以进行unicode编码
1 | |
s操作符可以识别十六进制
1 | |
使用内置函数绕过
这里涉及到一对概念:可迭代对象和迭代器,最经典的迭代器就是python的for循环
1 | |
python中的可迭代对象
序列类型
- 列表(List):[1,2,3,4,5]
- 元组(Tuple):(1,2,3)
- 字符串(String):”Hello World”
映射类型
- 字典:{1:’One’,2:’Two’}
- Tip:字典本身是不可迭代的(字典迭代实质上是迭代其键,使用keys(),values()或items()方法可以分别迭代键、值或键值对),但在python3.3开始,字典也成为了可迭代对象,迭代时会返回其键
集合类型
- 集合(Set):{1,2,3}
- 不可变集合(frozenset):frozenset({1,2,3})
迭代器类型
- 自定义迭代器类(实现
__iter__和__next__()方法) - 内置迭代器对象,如range(5)或者iter()函数创建的迭代器
文件对象
- 打开的文本文件或二进制文件,可通过逐行读取进行迭代
生成器表达式
- (x*x for x in range(5))
其他内置可迭代对象
- enumerate对象(enumerate(list))
- zip对象(zip(list1,list2))
- reversed对象(rebersed(list))
只要一个对象实现了 __iter__() 方法且该方法返回一个迭代器对象,那么这个对象就被认为是可迭代的。在Python中,可以使用 isinstance(obj, collections.abc.Iterable) 来检查一个对象是否是可迭代的
参考payload
1 | |
使用类的__new__()构造方法绕过
1 | |
可以触发类的__new__()函数的,所以在某些时候可以寻找可用的__new__()方法进行绕过
使用map(),filter()函数绕过
这两个函数时python的内置函数
1 | |
返回一个将 function 应用于 iterable 的每一项,并产生其结果的迭代器。 如果传入了额外的 iterables 参数,则 function 必须接受相同个数的参数并被用于到从所有可迭代对象中并行获取的项。 当有多个可迭代对象时,当最短的可迭代对象耗尽则整个迭代将会停止
1 | |
使用 iterable 中 function 返回真值的元素构造一个迭代器。 iterable 可以是一个序列,一个支持迭代的容器或者一个迭代器。 如果 function 为 None,则会使用标识号函数,也就是说,iterable 中所有具有假值的元素都将被移除
这两个函数都返回一个迭代器,所以我们需要使用list()函数将其变为一个列表输出
payload
1 | |
map()和filter()创造的迭代器有一个叫做”懒惰”的特性,也就是需要迭代一次,才能让func调用iterator里的值.所以我们就需要使用__next__()方法对map()创建的迭代器进行迭代